Model Guide (NC and BVC)
This guide shows best practices for selecting the right Noise Cancellation and Background Voice Cancellation models.
Introduction
Krisp SDK consists of two primary components - the SDK and the AI models.
- The SDK takes the AI model as an input. A single instance of the model can simultaneously process one or many audio streams.
- Each model is a file with a “kef” extension.
- Conceptually, the audio is processed in the AI model, and the SDK interprets the model for audio processing.
The following diagram demonstrates audio processing.
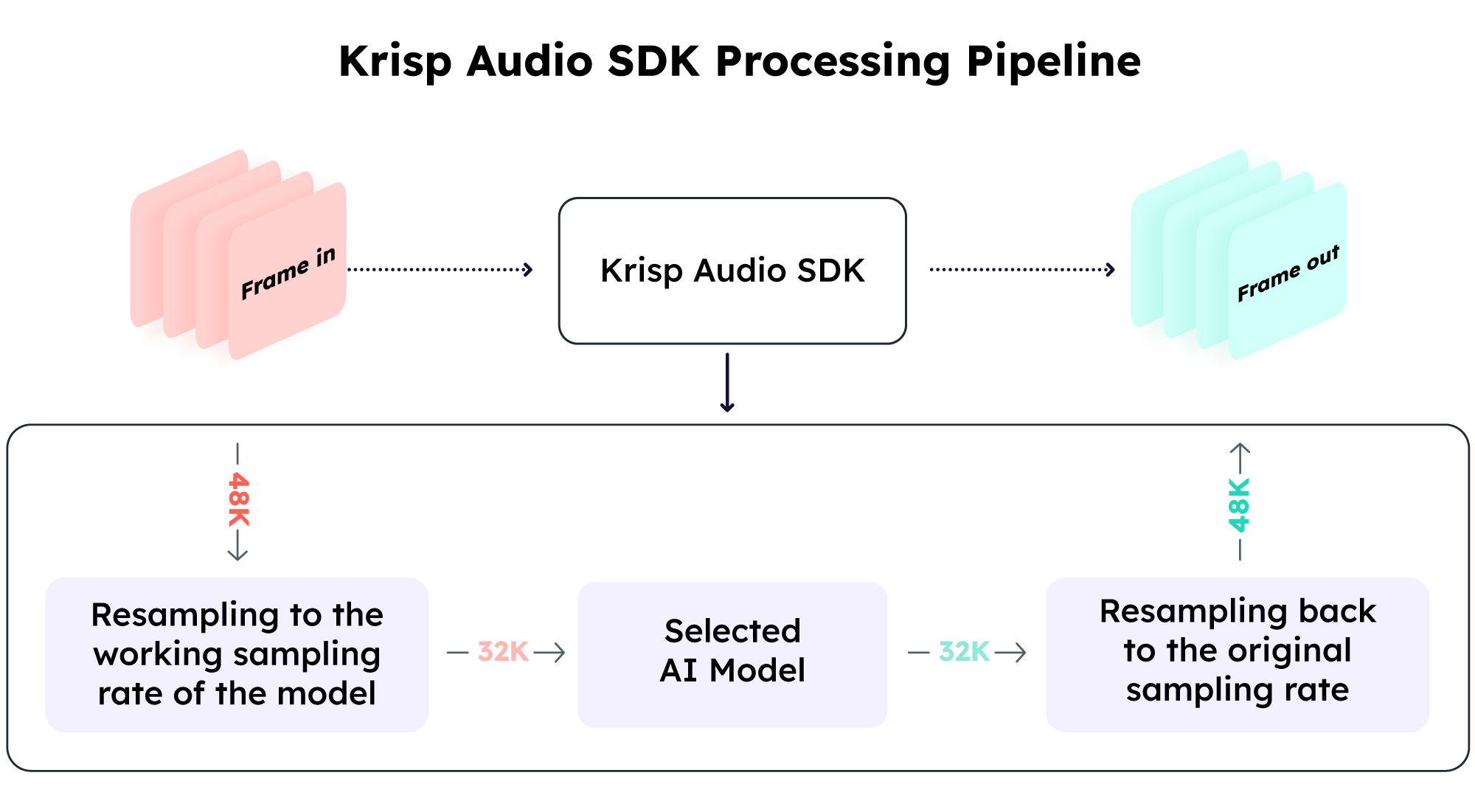
*The input and output 48kHz sampling rate of the stream is configurable.
*The 32kHz working sampling of the model depends on the selected model.
- The audio is resampled to the operational sampling rate of the model.
- The audio is processed using the AI model at the operational sampling rate.
- The audio is resampled back to the original sampling rate.
Outbound vs Inbound Stream Use Cases
Krisp provides dedicated AI models to clean background noise and voices from the microphone (outbound/uplink) and speaker (inbound/downlink) audio streams.
Krisp provides multiple models. Each model is unique, and optimized for specific use cases, however, all models are optimized for the inbound (speaker) or outbound (microphone) use case.
The outbound (microphone) models should not be used on the inbound (speaker) streams, and the inbound models should not be used on the outbound streams as Krisp’s AI model training is optimized for different audio streams..
Outbound Models:
- Trained to handle single-speaker
- Designed to work with raw unmodified audio directly from the mic
- Provide the market-best voice quality for the microphone stream
Inbound Models:
- Trained to handle the challenges of multi-speaker scenarios with various background noises and acoustic environments
- Designed to tolerate voice quality loss caused by lossy audio codecs
- Designed to tolerate voice degradations caused by the noise cancelation effects with the conferencing apps
Outbound models are optimized for the case of a single main speaker and raw microphone inputs, and using them for multi-voice scenarios or on streams degraded by lossy network codecs may lead to suboptimal performance, including voice suppression. Conversely, using inbound models for outbound audio may not achieve the same level of performance as outbound models specifically designed for raw microphone inputs.
Multivoice Limitations
Krisp inbound tech is not designed for multiple simultaneous voices on the same microphone. Inbound models are trained to handle multiple voices, each voice with its own mic, acoustic environment, and network-bound degradation.
Outbound (Microphone) Noise Canceling Models
Standard NC Models
Krisp outbound NC bundle includes standard 3 NC models:
| NC Quality | Sampling Rate | Model Name | Old Name | Size | Recommendations |
|---|---|---|---|---|---|
| High | 32kHz | krisp-nc-o-pro-v1 | c8.f.s.026300 | 5.8MB | Outstanding quality with balanced CPU usage |
| Medium | 32kHz | krisp-nc-o-med-v7 | c6.f.s.da1785 | 5.7MB | Use on mobile and power-limited systems |
| Low | 16kHz | krisp-nc-o-lite-v1 | c5.w.xs.c9ac8f | 2.8MB | Use only when low CPU usage is an absolute priority |
Model Size and Architecture Matters
Bigger models usually consume more CPU. However, varying CPU consumption can also result from differences in the models' underlying architecture. For example, high and medium-quality NC models have almost the same size, but the high-quality model consumes significantly more CPU due to its different architecture.
Dedicated NC 8kHz Model
Krisp standard outbound NC models are designed to work with sampling rates above 8kHz.
For sampling rates 8kHz and below we have an on-demand available NC solution not included in the standard bundle.
| NC Quality | Sampling Rate | Model Name | Old Name | Size | Recommendations |
|---|---|---|---|---|---|
| Medium | 8kHz | krisp-nc-o-nb-v2 | c5.n.s.20949d | 2.8MB | Should be used with sampling rates up to 8kHz inclusive |
Large Models
Large and CPU-demanding models are available for evaluation upon request. Check with your Krisp application engineer to access larger models. Krisp’s standard models are used across more than 150M users globally. Some partners require additional voice processing performance due to challenging noise distractors and SNR conditions.
Large vs. Standard NC Models
- Large models provide the best noise cancellation quality for extreme noise and SNR conditions but consume more CPU resources.
- Standard models are optimized for low CPU utilization and power efficiency, providing market-best noise cancellation quality across most use cases.
- Large models generally respond faster to noise condition changes, minimizing noise leakage.
Outbound (Microphone) BVC Models
BVC models
The standard BVC model is designed to remove background noises and voices. The BVC model has built-in NC. You should never use two Krisp NC/BVC models on the same audio stream.
Krisp BVC technology has two primary requirements:
- The sampling rate of the voice in the audio should be above 8kHz.
- A headset or compatible device from the list should be used
Please use regular NC models if one of these requirements is unmet.
Quality | Sampling Rate | Model Name | Old Name | Size | Recommendations |
|---|---|---|---|---|---|
High | 32kHz | krisp-bvc-o-pro-v3 | hs.c6.f.s.de56df | 14.7MB | Preferred choice for headset and earbuds. |
Medium | 16kHz | krisp-bvc-o-lite-v2 | hs.c6.w.s.087e35 | 8.6MB | Use only when low CPU usage is an absolute priority. |
Large BVC Models
Are available on demand. Contact your Krisp application engineer to access them for evaluation.
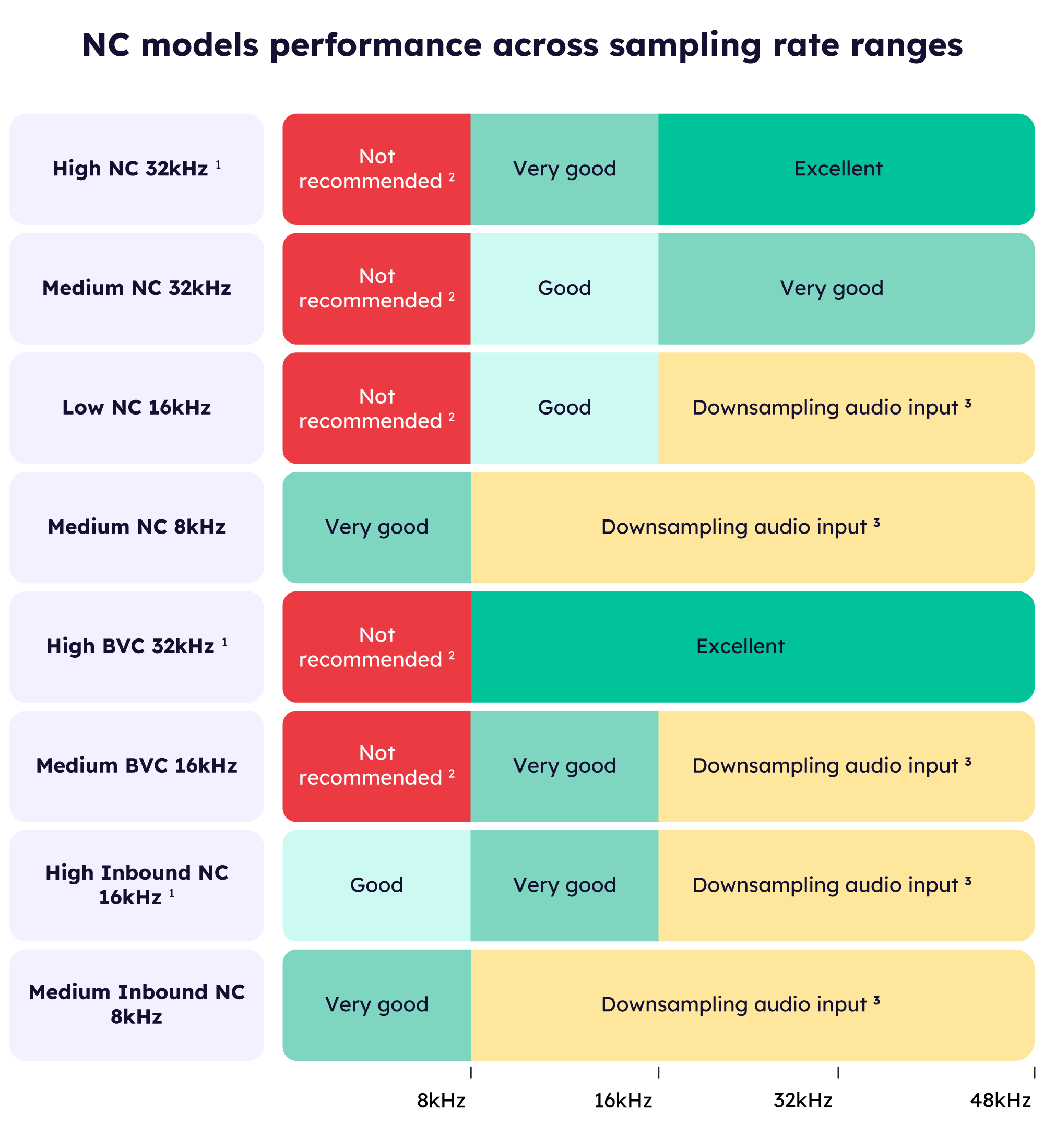
- Sampling rates above 32kHz will be downsampled and will not be noticeable by the human ear.
- Not recommended because of over-aggressive noise canceling.
- Audio resolution loss happens when the audio input is downsampled to match the model's sampling rate.
Inbound (Speaker Stream) Noise Canceling Models
Inbound Models For Telephony and Conference Applications
The inbound models are well-trained to tolerate:
- Possible voice degradations caused by the network audio codecs.
- Voice degradations caused by the noise cancelation effects with the conferencing apps.
- Other voice-processing effects.
- Challenges of the multi-speaker scenarios with various background noises and acoustic effects.
NC Quality | Sampling Rate | Model Name | Old Name | Size | Recommendations |
|---|---|---|---|---|---|
Medium | 8kHz | krisp-nc-i-nb-lite-v2 | c7.n.s.9f4389 | 4.1MB | Designed specifically for call operations inbound use cases. |
High | 8kHz | krisp-nc-i-nb-pro-v1 | c8.n.s.4abb08 | 3.6MB | Designed specifically for call operations inbound use cases. |
High | 16kHz | krisp-nc-i-wb-pro-v3 | c8.w.m.d266be | 13MB | Optimized for inbound conference calls. |