Voice Isolation
Krisp VIVA SDK is integrated into the audio pipeline on servers to clean background noises and voices from audio streams. For example, putting Krisp Voice Isolation models before Voice Activity Detection (VAD) in the audio pipeline results in much better “turn detection” (aka “unwanted interruptions”) for Conversational AI applications.
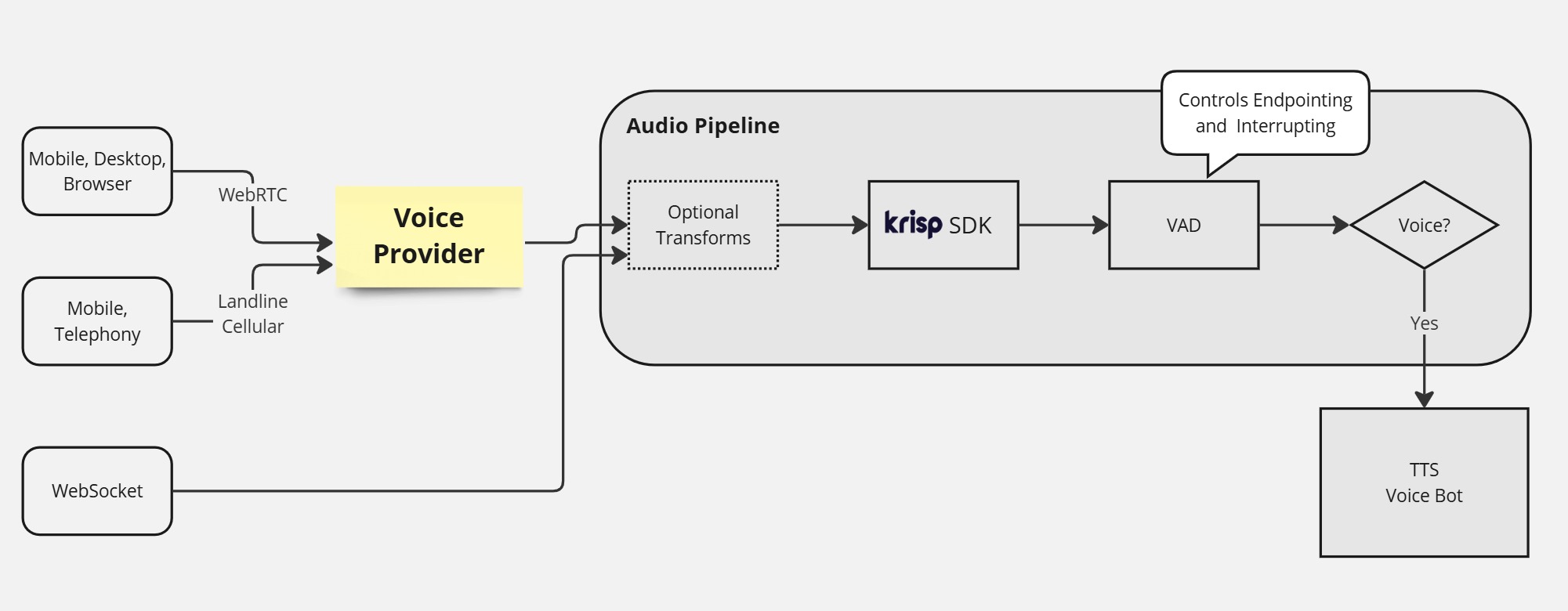
Use Cases
- Voice AI Agents
- Speech-to-Speech models
Multiple Audio Stream Support
Krisp VIVA SDK supports the real-time processing of multiple audio streams using a single model loaded into memory, ensuring efficient memory utilization.
Demo
Demo with Daily using Pipecat and Google Gemini Live
Getting Started
Here is an example showing how to use Voice Isolation in production.
Recommended Models
Krisp offers different voice isolation models optimized for different use cases, as shown in the following table.
krisp-viva-telandkrisp-viva-tel-litemodels are designed for telephony use case (up to 16kHz). Designed to isolate the primary speakers voice.krisp-viva-promodel removes background speech and noises and isolates only the primary speaker's voice. The model requires that the user speak close to the microphone.krisp-viva-ssmodel removes background noises. The ss (smart-speaker) model is compatible with smart-speaker and far-field audio capture use cases.
| Audio Source | Voice Isolation | Krisp Model |
|---|---|---|
| Telephony, Cellular, Landline, Mobile, Desktop, Browser (up to 16kHz) | + | krisp-viva-tel-v2, krisp-viva-tel-lite-v1 |
| Mobile, Desktop, Browser (WebRTC, 16-32kHz) | + | krisp-viva-pro-v1 |
| Mobile, Desktop, Browser (WebRTC, 16-32kHz) | - | krisp-viva-ss-v1 |
Automatic Resampling
Krisp Audio SDK will automatically resample the audio input to match the sampling rate of the model.
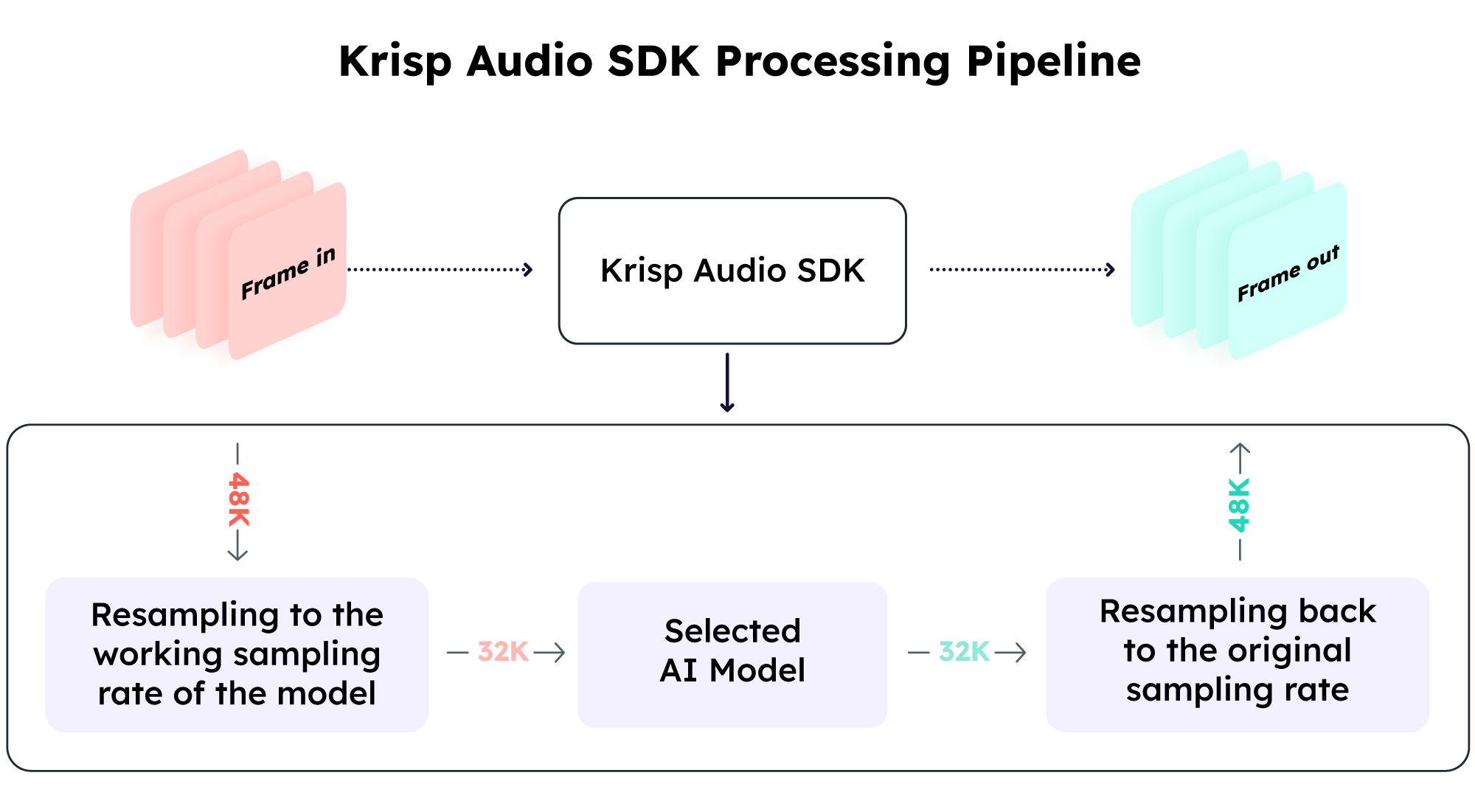
*The input and output 48kHz sampling rate of the stream is configurable.
*The 32kHz working sampling of the model depends on the selected model.
- The audio is resampled to the operational sampling rate of the model.
- The audio is processed using the AI model at the operational sampling rate.
- The audio is resampled back to the original sampling rate.
Updated 8 months ago